Extreme Optimization for Your Linux HPC Workloads
30+ Years of Expertise to Boost Your HPC Performance
DIAGNOSTIC
Precise Performance Evaluation of Your Codes
Detailed Analysis to Optimize Your Resources
Clear Reports for Informed Decisions
OPTIMIZATION
TRAINING
HPC Linux Expertise
FULL SCOPE OF EXPERTISE






DML-HPC Company
Company founded in 2022
Our founder is a top HPC expert with over +30 years of experience in extreme performance tuning in all HPC domains and senior architect in EMEA for more than 10 years; former DT at HPE.
We are a boutique specialist in code optimization for high-performance Linux environments. We help labs, scale-ups, research institutions, and enterprises achieve massive efficiency gains on existing hardware — without buying new servers.
Real-world impact: up to 10x speedups routinely on critical kernels and workloads through deep low-level tuning, algorithmic redesign, vectorization, memory hierarchy mastery, and energy-aware transformations.
We operate worldwide, helping companies solve their most challenging HPC code optimization problems. We have already assisted dozens of major international groups across critical sectors including:
Oil & Gas (exploration, reservoir simulation)
CAD/CAE & Scientific Computing (CFD, physics, Chemistry)
Banking & Finance (risk modeling, quant simulations)
Weather & Climate Modeling
PERFORMANCE DIAGNOSTIC & CODE EVALUATION
PRE-PURCHASE INFRASTRUCTURE BENCHMARKING
STRATEGIC ADVISORY
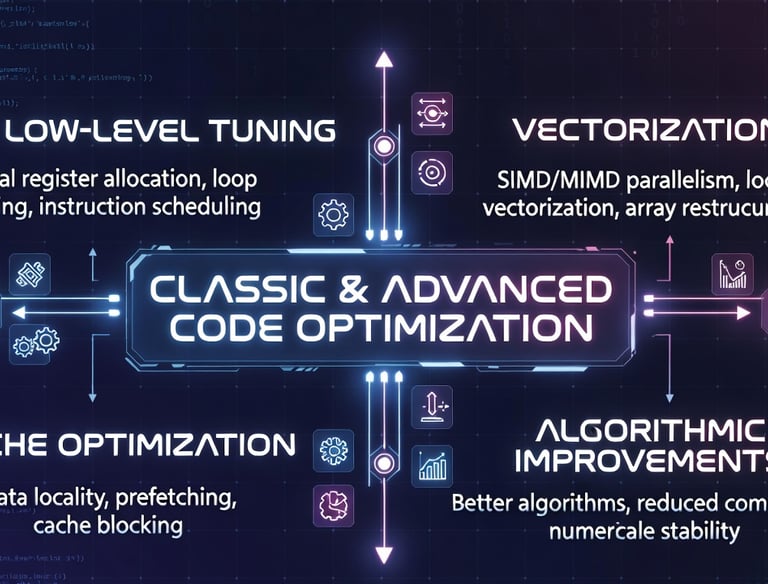
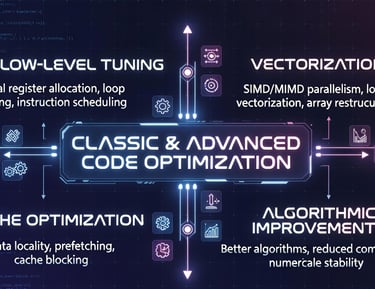
CLASSIC & ADVANCED CODE OPTIMIZATION
ROUTINELY DELIVERING 3× to 10× SPEEDUPSADVANCED TUNING TRAINING
METHODOLOGY TRANSFER
CODE TRANSFORMATION & PLATFORM MIGRATION
Our Services
Experts in HPC Optimization, Benchmarks, and Tailored Training
Performance Diagnostic & Code Evaluation
In-depth profiling and assessment of your existing codes to identify bottlenecks, quantify inefficiencies (compute, memory, I/O, IB fabric), and precisely estimate achievable speedups and energy savings.
Benchmarking
Structured reflection, custom benchmark design, and performance modeling before investing in new hardware — ensuring the best fit for your workloads (Intel / AMD / NEC CPUs, GPU accelerators, hybrid architectures).
Deep low-level tuning including vectorization, loop transformations, cache optimization,bindings, kernel settings, storage, fabric, and algorithmic improvements — routinely delivering 3× to 10× speedups on large workloads. Economy driven strategies.
Classic & Advanced Code Optimization
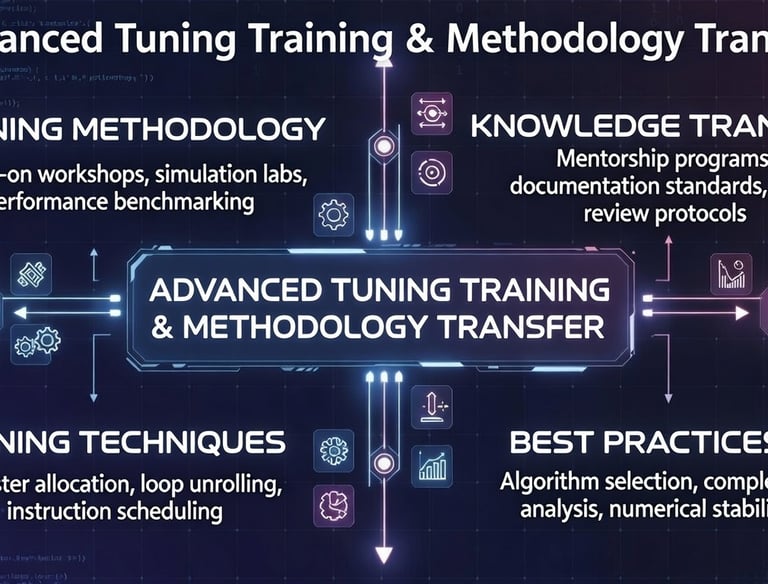
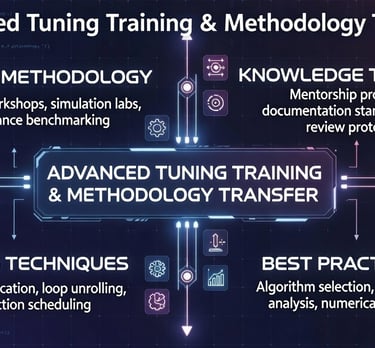
Advanced Tuning Training & Methodology
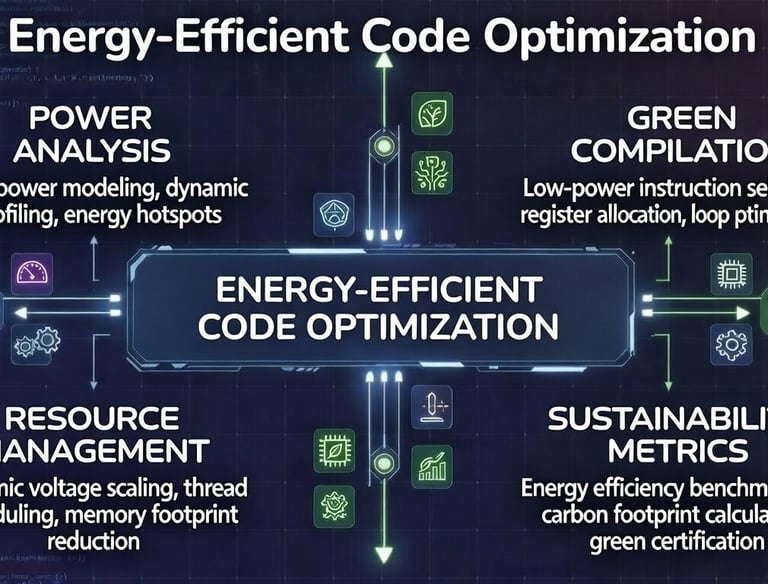
Energy-Efficient Code Optimization
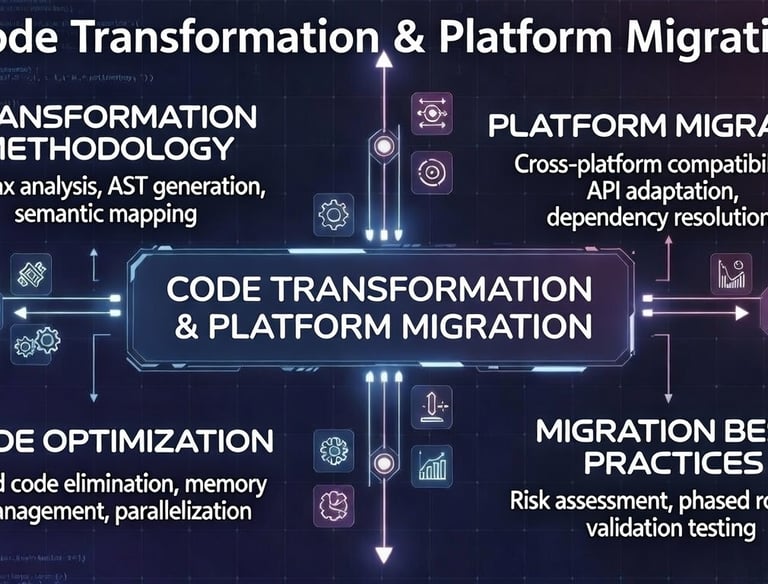
Code Transformation & Platform Migration
Hands-on advanced training sessions covering performance engineering best practices, profiling & tuning tools, code instrumentation, reproducible optimization workflows, and transfer of cutting-edge methodologies to your teams.
Porting and refactoring of codes across hardware platforms: Intel, AMD, ARM, CPU-to-GPU/accelerator , adaptation to multi-core / many-core / GPU architectures, and modernization of legacy Fortran/C/C++ HPC applications.
Power-aware code transformations: dynamic voltage and frequency scaling exploitation, precision reduction, memory access pattern optimization, algorithmic changes for lower power draw — significantly reducing energy consumption and TCO in large-scale data centers.
Advanced Tuning Training & Methodology


The DML-HPC Optimization Approach
HPC Performance Structural Analysis & Code Cleanup
1. ObjectiveTargeted intervention on HPC codebases (CPU, MPI, OpenMP, Fortran/C++/ASM) aimed at:
Characterizing the actual low-level runtime behavior
Modeling the theoretical peak performance achievable on the target platform
Identifying the dominant structural inefficiencies
Closing the gap between observed and potential performance
This service is designed for environments where performance represents a measurable technical and economic challenge.


2. Technical Scope
The analysis is based on:
Low-level profiling (validated cycles, instructions, hardware signals)
Calibrated micro-benchmarks
Experimental correlation (code architecture)
Modeling of the dominant execution regime (compute-bound, memory-bound, synchronization, dependency)
Hardware performance counters are used critically and validated through controlled experimentation
The goal is to observe the true execution reality, rather than interpreting isolated metrics.
3. Methodology - Phase 1 – Pre-Study (≤ 1 week)
Prerequisites:
Source code frozen
Dataset fixed and representative
Numerical validation criterion clearly defined (bit-exact or specified tolerance)
Dedicated and stable target platform
Full access to hardware performance counters
Work performed:
Low-level profiling of the existing code
Identification of the dominant execution regime
Modeling of the theoretical performance ceiling on the target platform
Estimation of short-term achievable gain
Identification of the main leverage points
Deliverable: Concise report including:
Current performance position
Estimated theoretical ceiling
Measured performance gap
Prioritized action plan
Estimated effort and probability of success per lever
If immediately exploitable quick wins are identified, they can be implemented during this phase
The pre-study is invoiced independently of the outcome
3. Methodology - Phase 2 – Targeted Intervention (weeks)
If the pre-study reveals significant leverage:
Measurable objective defined (benchmark, dataset, time-based metric)
Platform frozen
Validation criterion fixed
The intervention targets a quantified goal (e.g. ×3, ×5, etc.)
//Performance-based compensation
3. Methodology - Phase 3 – Heavy Transformations (optional)
When the targeted gain requires:
Algorithmic redesign
Deep code restructuring
Major memory layout overhaul
A specific plan is proposed, including effort estimation (e.g. 3 months), probability of success, and adapted contractual conditions
4. Technical Requirements
Dedicated machine (cloud or on-premise)
Sufficient administrative / root-equivalent access
Freedom to install profiling tools
Stable environment throughout the analysis period
Without these conditions, results cannot be guaranteed


5. Positioning
This intervention does not aim at marginal fine-tuning. It targets major structural inefficiencies — often logical consequences of historical code evolution and the increasing complexity of modern architectures.
The goal is to restore coherence between:
The execution model embodied in the code
The actual micro-architectural reality of the processor




6. Commitment
Before any engagement, the following must be clearly established:
Economic stakes of the computation
Business impact of a significant performance gain
Final decision-maker
In the absence of a clear business case, the intervention is not undertaken
7. Nature of the Approach
The approach is strictly observational. It relies on:
Measurement
Experimental correlation
Identification of the dominant limiting factor
Reduction of the gap to the physical ceiling
No assumptions are made a priori; the diagnosis is driven purely by observed execution reality
Contact
Expert HPC consulting tailored to your needs
telePhone
contact@dml-hpc.com
+33 672 993 615
©DML-HPC 2026. All rights reserved.
address
paris, FRANCE